The Data
Source
Our project examines the predictors of interest rates in an online peer-to-peer lending marketplace.
Using data from the Lending Club, we examine 887,379 unique loans issued between 2007 and 2016 (source).
Basic summary stats
The average loan amount is $14,755, with most loans (67%) still being active, a sizable minority (23%) already paid off, and the remaining in various states of tardiness, default, and charge-off. (Charge-off occurs when a creditor declares that a debtor is no longer able to pay the loan; usually, this can happen after loan payments are six months behind schedule.)
All borrowers are assigned a FICO score - something which should signal a borrower’s riskiness to potential creditors. Scores range from A (least risky) to G (most risky). Less than 10% of borrowers have scores below D - the majority are in the top three (least risky) ranges: A (17%), B (29%), and C (28%). Borrowers are then ‘priced’ according to their riskiness, and this is reflected in the interest rates. Indeed, while the average interest rate across all loans was 13%, this varies substantially by grade.
| Grade | Interest rate (%) |
| A | 7.24 |
| B | 10.83 |
| C | 13.98 |
| D | 17.18 |
| E | 19.90 |
| F | 23.58 |
| G | 25.63 |
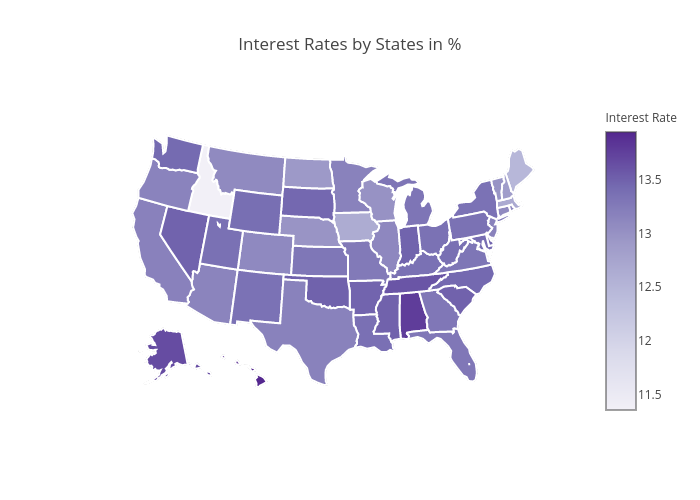
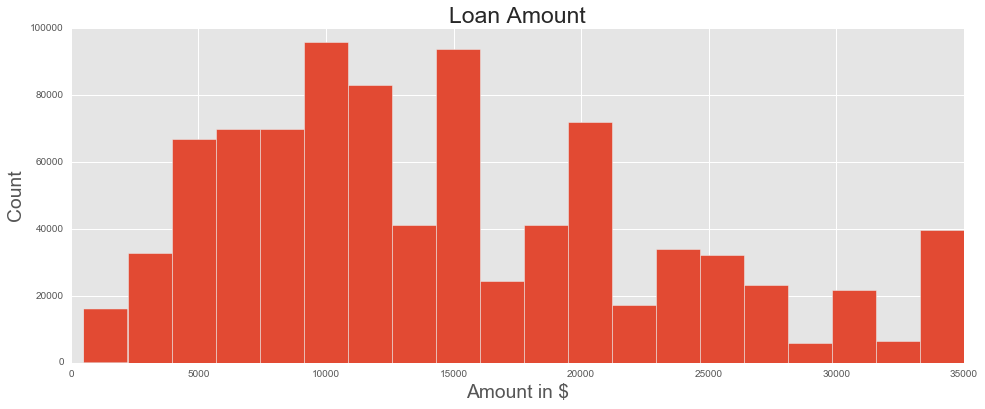
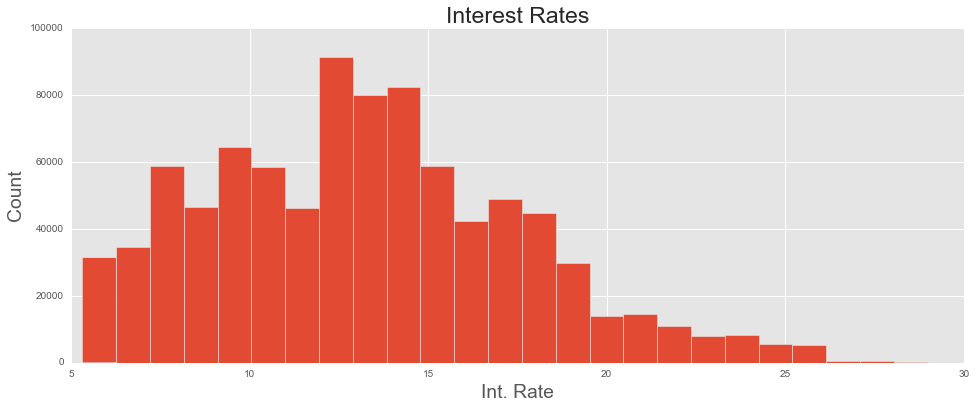
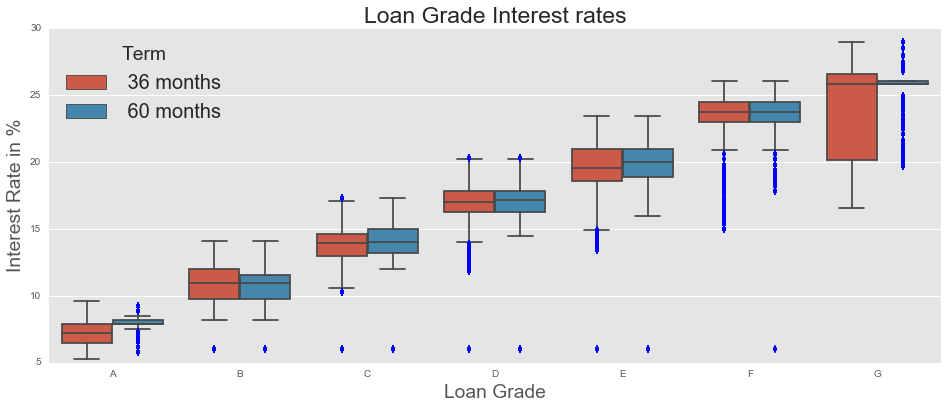
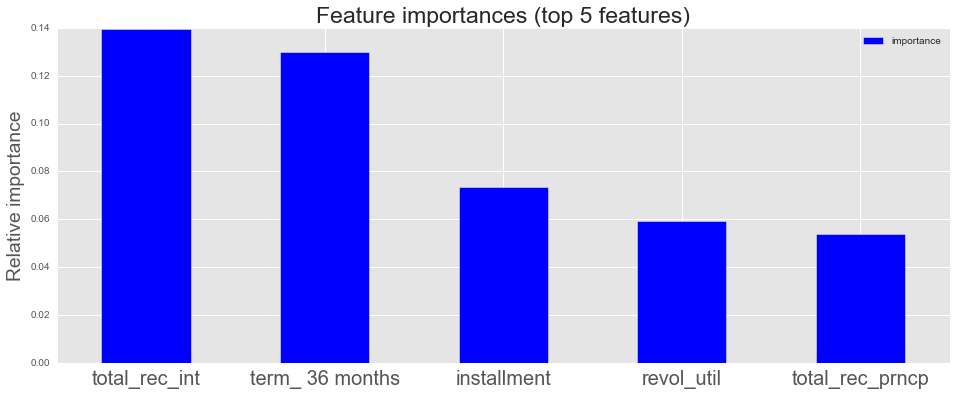
As expected, the interest rate is positively correlated with loan grade: as loans get riskier, borrowers must pay more to lenders to take on that risk.
A strategy forward
Interest rates are directly correlated with a borrower's grade, but that does not necessarily provide us with much useful information: both the interest rate and grade of a borrower are attempting to capture the same thing (riskiness). So a better question to ask is: what could predict a borrower’s riskiness? Possible predictors include individual-level characteristics which are measurable but may not be available in this dataset (education, employment status, social network, spending behavior), measurable and available in this dataset (debt-to-income ratio, purpose of loan), and difficult to measure altogether (risk tolerance, likelihood of exogenous income or spending shocks).
Considering information which is available in the Lending Club dataset: The majority of loans (59%) are used to consolidate debt. This becomes 82% if we include credit card payments. In other words, the majority of borrowers on Lending Club are borrowing in order to pay off other debt. This seems to imply that the Lending Club data is a selected sample, not necessarily representative of the entire population of borrowers. Indeed, Lending Club seems unlikely to be the first ‘port of call’ for borrowing; rather, we could speculate that most borrowers go to Lending Club when they are further along their debt journey.
The debt-to-income (DTI) ratio is 18% - meaning, the average LC borrower must spend around 18% of their monthly income on their other loans (excluding mortgages and the requested LC loan). In general, we can expect that borrowers with higher DTI ratio will have more difficulty in paying off their loan - a predictor for default, and also, perhaps, a predictor for higher interest rates. The DTI distributions also shift according to grade: with less risky borrowers having lower DTI ratios, on average, than more risky borrowers.